





 There’s a part of data science that you rarely hear about: the deployment and production of data flows. Everybody talks about how to build models, but little time is spent discussing the difficulties of actually using those models. Yet these production issues are the reason many companies fail to see value come from their data science efforts and investments.
There’s a part of data science that you rarely hear about: the deployment and production of data flows. Everybody talks about how to build models, but little time is spent discussing the difficulties of actually using those models. Yet these production issues are the reason many companies fail to see value come from their data science efforts and investments.
The data science process is extensively covered by resources all over the web and known by everyone. A data scientist connects to data, splits it or merges it, cleans it, builds features, trains a model, deploys it to assess performance, and iterates until she’s happy with it. That’s not the end of the story though. Next, you need to try the model on real data and enter the production environment.
These two environments are inherently different because the production environment is continuously running – and potentially impacting existing internal or external systems. Data is constantly coming in, being processed and computed into KPIs, and going through models that are retrained frequently. These systems, more often than not, are written in different languages than the data science environment.
To better understand the challenges companies face when taking data science from prototype to production, Dataiku, the maker of the all-in-one collaborative data science platform Dataiku DSS, recently asked thousands of companies around the world how they do it. The results show that companies using data science have unique challenges that fall into four different profiles that they’ve coined as follows: Small Data Teams, Packagers, Industrialisation Maniacs, and The Big Data Lab.
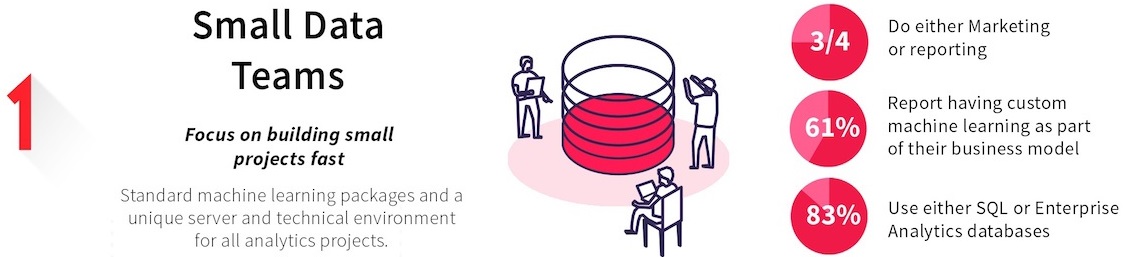
Small Data Teams (23%)
Small Data Teams focus on building small projects fast: standard machine learning packages with a unique server and technical environment for all analytics projects.
- 3/4 do either Marketing or reporting
- 61% report having custom machine learning as part of their business model
- 83% use either SQL or Enterprise Analytics databases
These teams, as their name indicate, use mostly small data and have a unique design /production environment. They deploy small continuous iterations and have little to no rollback strategy. They often don’t retrain models and use simple batch production deployment, with few packages. Business teams are fairly involved throughout the data project design and deployment.
Average level of difficulty of deployment: 6.4
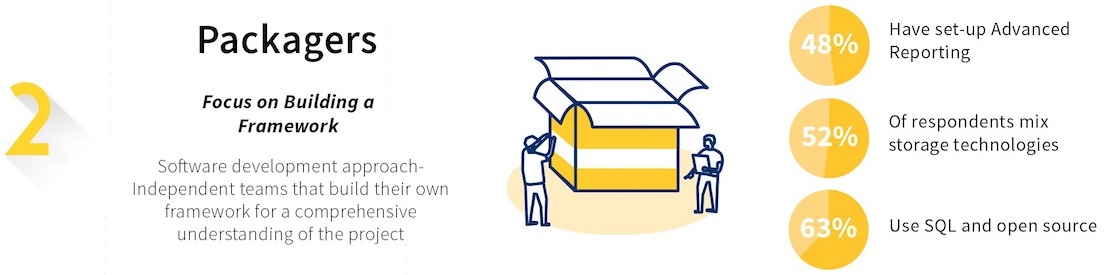
Packagers (27%)
Packagers focus on Building a Framework (the software development approach): independent teams that build their own framework for a comprehensive understanding of the project.
- 48% have set-up Advanced Reporting
- 52% of respondents mix storage technologies
- 63% use SQL and open source
These teams have a software development approach to data science and have often built their framework from scratch. They develop ad-hoc packaging and practice informal A/B testing. They use Git intensely to understand the globality of their projects and their dependencies, and they are particularly interested in IT environment consistency. They tend to have a multilanguage environment and are often disconnected from business teams.
Average level of difficulty in deployment: 6.4
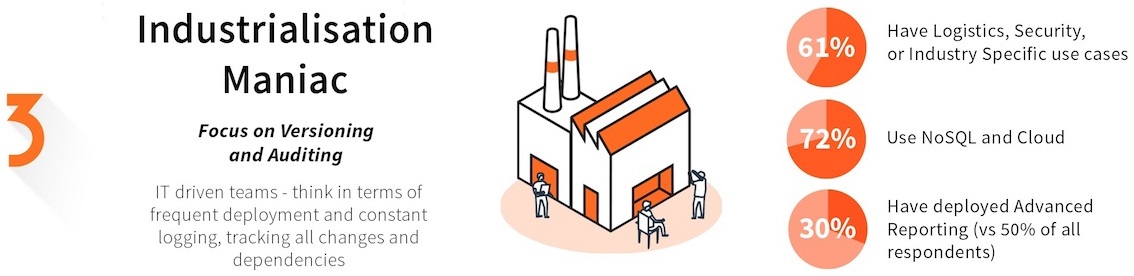
Industrialisation Maniacs (18%)
Industrialisation Maniacs focus on Versioning and Auditing: IT-driven teams that think in terms of frequent deployment and constant logging to track all changes and dependencies.
- 61% have Logistics, Security, or Industry Specific use cases
- 30% have deployed Advanced Reporting (vs 50% of all respondents)
- 72 % use NoSQL and Cloud
These data teams are mostly IT-led and don’t have a distinct production environment. They have complex automated processes in place for deployment and maintenance. They log all data access and modification and have a philosophy of keeping track of everything. In these setups, business teams are notably not involved in the data science process and monitoring.
Average level of difficulty in deployment: 6.9
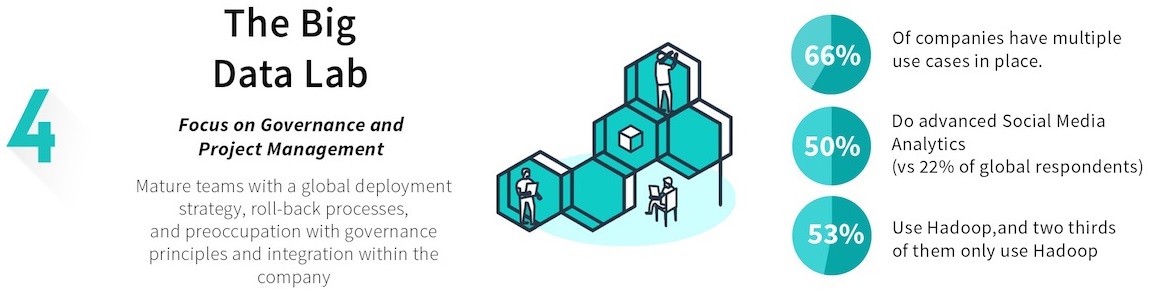
The Big Data Lab (30%)
The Big Data Lab focus’ on Governance and Project Management: Mature teams with a global deployment strategy, rollback processes, and preoccupation with governance principles and integration within the company.
- 66% of companies have multiple use cases in place
- 50% do advanced Social Media Analytics (vs 22% of global respondents)
- 53% use Hadoop and two thirds of them only use Hadoop
These teams are very mature with more complex use cases and technologies. They used advanced techniques such as PMML, multivariate testing (or at least formal A/B testing), have automated procedures to backtest, and robust strategies to audit IT environment consistency. In these larger, more organized teams, business users are extremely involved before and after the deployment of the data product.
Average level of difficulty in deployment: 5.6
Overall, the main reported barrier to production for all groups (50% of respondents) is data quality and pipeline development issues. In terms of the overall difficulty of data science production, the average reported difficulty of deploying a data project into production is 6.18 out of ten, and 50% of respondents’ state that on a scale of 1 to 10, the level of difficulty involved in getting a data product in production is between six and 10.
Considering the results, these are a few principles that companies should keep in mind on how to build production-ready data science products:
- Getting started is tough. Working with small data on SQL databases does not mean it’s going to be easier to deploy into production.
- Multi language environments are not harder to maintain in production, as long as you have an IT environment consistency process. So mix’n’match!
- Real-time scoring and online machine learning are likely to make your production pie more complex. Think about whether the improvement to your project is worth the investment.
- Working with business users, both while designing your machine learning project and after when monitoring it day to day, will increase your efficiency. Collaborate!



No Comment